Wise Words of Ovid
A wise bot retrieving quotes from antiquity
"The mind which is conscious of right, rectitude, undeviating integrity, despises, laughs at, treats with contempt, the lies of rumor."
Problem Definition and Goal
Challenge
Generally, to reply to a different X tweets (often political or opinionated in nature) with a quote that strikes a neutral tone. Depending on humerous/ironc/sarcastic tone if comment is overtly negative.
- Prompt-based “wisdom” responses based on sentiment using cardiffnlp/twitter-roberta-base-sentiment. E.g.:
“Here is why I think we’re seeing this: Time & time again, the media focuses on polls & draws conclusions about the state of the race without focusing on 1.) all Democrats have done & 2.) the real threat of Trump/MAGA extremism. But VOTERS ARE NOT DUMB! Wake up, media.”
Goal
- Replying to tweets with relevant quotes.
- Using sentiment analysis to determine tone (e.g., humorous, neutral).
Generating/Extracting Quotes:
Data and Challenges
Most of the works are found easily online written in poetic form which is not as straight-forward to parse as regular documents. Found a vast improvement in text extraction from Ovid works using 300 dimension vs 200 dimension embeddings. This is consistent with many of the recommendation for creating RAGs.
- Data: Extracting quotes from Ovid’s poetic works.
- Key Challenges:
- Parsing poetic text.
- Avoiding hallucinations in LLM-generated quotes.
Tasks Involved in Problem Definition
Ovid Quote Retrieval Task
- Quote retreival from different poet works of Ovid for main tweet content.
- Quote generation using different LLMs
- The expected challenge of hallucinations arises here particurly when the LLM was not allowed to choose which person it was quoting
- RAG: E.g. “What did Ovid have to say about different political parties”
- Sentence-similarity (see Is Cosine-Similarity of Embeddings Really About Similarity?) which was most useful in weeding out totally useless chunks of text. However, as far as generating memorable quotes similar in concept even it was not so much:
- Input sentence: Plurality should never be proposed unless needed. (William Occam)
-
Output sentence 1: Everything should be made as simple as possible, but not simpler. (Albert Einstein) 0.217 similarity using MLX LLM -
Output sentence 2: Simplicity is the ultimate sophistication. ( Leonardo da Vinci) 0.175 similarity using MLX LLM
- Quote generation using different LLMs
- Responses:
- RAG-based:
- Metrics:
- Context Relevance: Ensuring the retrieved context is pertinent to the user query, utilizing LLMs for context relevance scoring.
- Groundedness: Separating the response into statements and verifying each against the retrieved context.
- Answer Relevance: Checking if the response aptly addresses the original question.
- Metrics:
- Political: For political determined the type of response (LLM can generate the actual text), sentiment can be used but also clustering may be useful Clustering Sentence Embeddings to Identify Intents in Short Text
- Take-away: RAG-based methods were better at making factual statements, e.g. “Who is Arachne?” -> “Arachne is the protagonist of a tale in Greek mythology known primarily from the version told by the Roman poet Ovid, which is the earliest extant source for the story.”. Subjective
- RAG-based:
Tweets needed: Tweet Probability of Repeated Occurrence over Time
Baseline for tweets retrieved needs to seed initial content with replacement.
\[\begin{equation*}P(\text{repeated in 2 weeks}) = 1 - \left( \frac{N - 1}{N} \right)^{\frac{14}{m}}\end{equation*}\]Substituting in the values:
\[\begin{equation*} P(\text{repeated in 2 weeks}) = 1 - \left( \frac{99}{100} \right)^{14}\end{equation*}\]Calculating this gives:
\[\begin{equation*} P(\text{repeated in 2 weeks}) \approx 0.135\end{equation*}\]Personally, I’d like it to be under 10% for a longer period of time (increases probability), so if I tweak the numbers a bit upping bank of tweets (N = 200 tweets) @ days = 21:
\[\begin{equation*}P(\text{repeated in 3 weeks}) \approx 0.0980\end{equation*}\]Interesting Quote “Hallucinations”:
- Fictitious author
- Prompt: Respond to every input with a quote from your peers and the first and last name of who said it.
- Input: “all of this has happened before, all of this will happen again” (Sam Altman)
- Output: “The only way to deal with the void is to continue to try to fill it.” - John Smith
- Fictitious quote from author:
- Prompt: Respond to every input with a quote from your peers and the first and last name of who said it.
- Input: Everyone talking re: over-education of youth. But that’s not the problem. Real issue is believing certain work is beneath you. We’ve all answered phones. Jensen Huang (NW $81B) cleaned toilets. I was broke prep cook in a Jewish deli. Gotta start somewhere
- Output: “Real issue is believing certain work is beneath you.” - Jensen Huang
- Postured quote: From no one in particular and not particularly memerable.
- Prompt: Generate a response to a self-promotional tweet expressing a strong stance against politics.
- Input: We all come from somewhere, but we’re all Americans.
- Output: “We all come from different places and backgrounds, but at the end of the day, we’re all Americans.” -Unknown
Fine-tuning based on gold standard
I wanted to see how much leverage I could get out of a few-shot training examples. I used the babbage-002 model so perhaps I would have gotten more leverage out of GPT3.*. Even so, the results were not encouraging for ~10 political tweet examples with glib and sometimes stoic quotes from figures such as MLK. It begs the question on how much effort is put into making an LLM work.
Gavin Newsom Tweet
Another day, another common sense gun safety law struck down by a right-wing judge.
This is exactly why we need to amend the U.S. Constitution and establish a Right to Safety. https://sandiegouniontribune.com/news/courts/story/2024-03-12/> san-diego-federal-judge-strikes-down-california-law-limiting-high-frequency-gun-purchases
Fine-tuned response
#2 VenezuelanCuban View Post Originally posted by Hopefully the whole country with be armed like in Venezuela.
It will be, but I don’t see how they will be armed. I don’t think it’s possible. They’re so used to the stateless existence that they will refuse to live under it. They will not adopt the military industrial complex mentality, which in their view is a tool of the state. They’ll have to form their own government. Only then can
Dual-Encoder:
A Dual-Encoder model can help with effective quote retrieval tailored to tweet contexts. This architecture excels in retrieval tasks by computing and comparing embeddings for two input types—in this case, tweet content and a collection of quotes from Ovid’s works.
Semantic Understanding: Dual-Encoders map inputs like tweets and quotes into high-dimensional embeddings that effectively capture their semantic meaning. This ensures the retrieved quote aligns with the tweet’s tone, sentiment, and context.
Scalability: Once encoded into embeddings, quotes can be efficiently searched using similarity measures such as cosine similarity. This approach is ideal for handling large datasets of poetic quotes, enabling real-time response generation.
Tailored Responses with Flexibility: Fine-tuning Dual-Encoder models allows for nuanced and highly relevant responses.
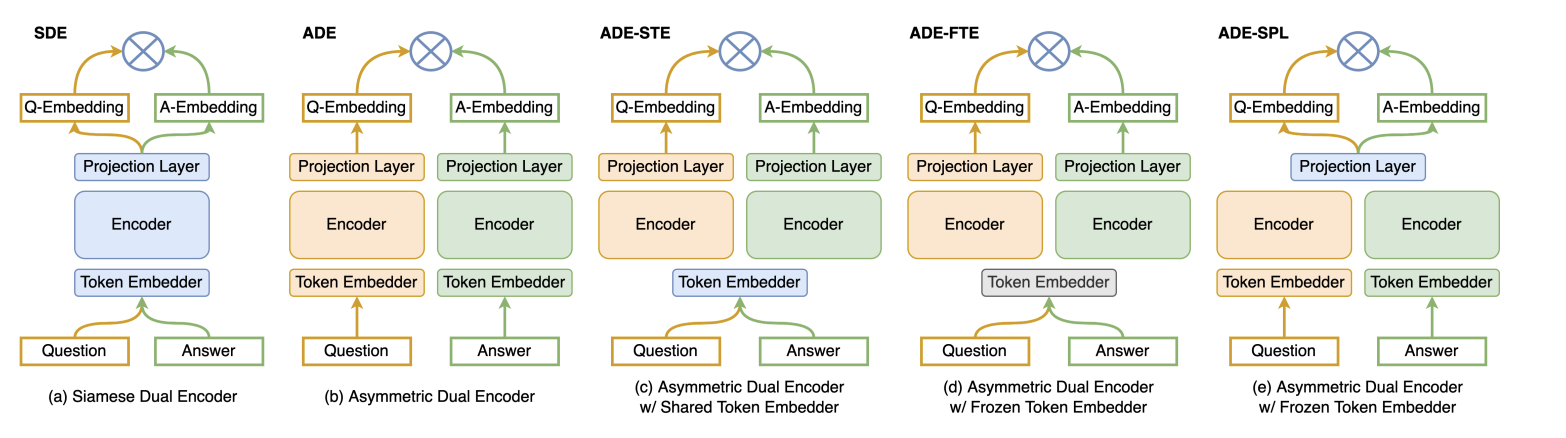
Technology Stack
Infrastructure:
- Digital Ocean Droplets utilized for hosting, ensuring efficient and scalable deployment.
- Github Actions employed for Continuous Integration/Continuous Deployment (CI/CD) and workflow automation, streamlining the development pipeline.
- X API for deployment
Machine Learning Stack:
- Leveraging Huggingface’s library for Twitter Sentiment.
- Incorporating OpenAI GPT-3.5 Turbo for queries
- Langchain integrated to handle specific language-related tasks involving GPT.
Model Training:
- Training/experimentation with natural language models on diverse datasets to enhance performance.
- Fine-tuning GPT-3.5 Turbo on domain-specific tasks, optimizing for accuracy and relevance.
Relevant Reading
- TWEETEVAL is a standardized test bed for seven tweet classification tasks. These are: sentiment analysis, emotion recognition, offensive language detection, hate speech detection, stance prediction, emoji prediction, and irony detection. TWEETEVAL: Unified Benchmark and Comparative Evaluation for Tweet Classification
Future Work
The current focus is on retrieval, but Dual-Encoders could evolve into a hybrid system that combines retrieval and generation. Using a recommendation system that understands context, relevance, and even mood, it could not only rank and refine retrieved quotes but also adapt or paraphrase them using a generative model. This approach ensures the insights provided are tailored, dynamic, and highly relevant.